Introduction
In today’s data-driven world, Database Management Systems (DBMS) play a pivotal role in organizing, storing, and retrieving vast amounts of information efficiently. Whether you’re browsing a website, making an online purchase, or analyzing business trends, chances are you’re interacting with a DBMS behind the scenes. In this blog post, we’ll dive into the fascinating world of DBMS architecture, exploring its fundamental components and shedding light on the magic that makes data management possible.
What is DBMS Architecture ?
DBMS architecture encompasses the structural framework and components comprising a software system dedicated to the management and manipulation of databases. A well-designed architecture ensures efficient storage, retrieval, and management of data while maintaining data integrity, security, and availability.
The architecture of a DBMS can exhibit variations contingent upon factors such as the DBMS type (relational, NoSQL, etc.), deployment models (centralized, distributed), and specific demands. A meticulously crafted architecture guarantees the DBMS’s capability to efficiently manage data, offer consistent performance, and cater to the requirements of both applications and users.
Anatomy of DBMS Architecture
Certainly! Let’s take a closer look at the intricate structure of a Database Management System (DBMS) architecture, where we’ll dissect its essential components and their respective functions:
- Data Storage Layer:
- Files and Data Structures: This layer bears the responsibility for the physical storage of data. In the context of a relational DBMS, data is organized into tables, where each table consists of rows (records) and columns (attributes). Diverse DBMS types might employ distinct data structures, such as key-value stores, document collections, or graphs.
- Query Processor:
- Query Parsing: The query processor plays a crucial role in interpreting user queries (SQL statements) and translating them into an internal representation.
- Query Optimization: It analyzes different ways to execute the query and selects the most efficient execution plan to retrieve the required data.
- Query Execution: The selected plan is then put into action, operating on the data storage layer to fetch or manipulate the data.
- Transaction Manager:
- Transaction Control: Overseeing the lifespan of transactions, it ensures strict adherence to ACID properties – Atomicity, Consistency, Isolation, and Durability.
- Concurrency Control: Coordinates simultaneous access to the database by multiple users, preventing data inconsistencies and ensuring isolation between transactions.
- Concurrency Control:
- Lock Manager: Implements locking mechanisms to control access to data, preventing conflicts between concurrent transactions.
- Timestamps and Ordering: Uses timestamps or other mechanisms to ensure a consistent order of transactions and maintain data integrity.
- Database Security:
- Authentication: Verifies user identities before granting access to the database.
- Authorization: Determines the permissions and privileges each user or role has within the database.
- Encryption: Protects data by encrypting it at rest and during transmission to prevent unauthorized access.
- Backup and Recovery:
- Backup Subsystem: Frequently generates backup copies of the database to guarantee the capability of data restoration in the event of a failure.
- Recovery Manager: Facilitates recovery after failures by restoring the database to a consistent state using transaction logs and backups.
- Database Catalog/Metadata Repository:
- Metadata Storage: Stores information about the database schema, tables, columns, indexes, constraints, and relationships.
- Schema Management: Allows the DBMS to understand the structure and organization of the data.
- User Interface:
- Command-Line Interface (CLI): Facilitating interaction, it empowers users to engage with the DBMS through text-based commands.
- Graphical User Interface (GUI): Provides a visual interface for managing the database.
- Application Programming Interface (API): Allows developers to integrate the DBMS functionality into their applications.
- Data Access Drivers:
- APIs and Protocols: Provides a standardized way for applications to communicate with the DBMS, allowing them to connect, execute queries, and retrieve data.
- Query Cache (Optional):
- Caching: Stores frequently accessed query results to improve query performance by reducing the need to access the underlying data storage layer.
- Query Logging and Monitoring (Optional):
- Query Logging: Records executed queries and their outcomes for analysis, debugging, and performance optimization.
- Performance Monitoring: Monitors system health, query performance, and resource utilization.
- Distributed Database Management (Optional):
- Distributed Data Storage: Manages data across multiple physical locations or nodes for scalability and fault tolerance.
- Replication and Sharding: Replicates or partitions data to distribute the workload and improve performance.
Types of DBMS Architecture
There are several types of DBMS Architecture that we use according to the usage requirements. Types of DBMS Architecture are discussed here.
- 1 – Tier Architecture
- 2 – Tier Architecture
- 3 – Tier Architecture
1 – Tier Architecture or Single – Tier Architecture
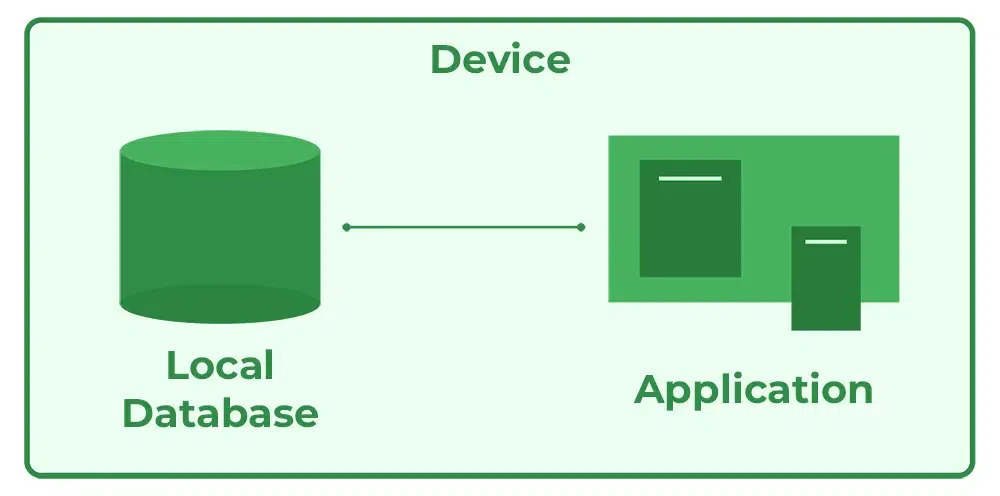
The one-tier architecture, also referred to as the Single-tier architecture, embodies a straightforward and uncomplicated software design strategy where all application layers amalgamate into a single executable or process.In this architecture, the user interface, business logic, and data storage are all contained within a single unit. While this architecture is not as common in modern complex applications, it still finds use in certain scenarios. Let’s explore the characteristics, advantages, and drawbacks of the one-tier architecture.
Characteristics:
- Single Unit: All components, including the user interface, business logic, and data storage, are bundled together as a single executable or process.
- Simplicity: One-tier architecture is relatively easy to design, implement, and manage due to its minimal complexity.
- Desktop Applications: It is commonly used for standalone desktop applications that do not require extensive scalability or distributed processing.
- Limited Separation: There is minimal or no separation between the different layers, which can make maintenance and updates challenging.
Advantages:
- Simplicity: One-tier architecture is straightforward to develop and deploy, making it suitable for small applications or prototypes.
- Performance: Since all components are within the same process, there is minimal overhead associated with communication between layers.
- Minimal Network Traffic: No network communication is needed between different tiers, reducing network-related performance bottlenecks.
- Resource Efficiency: This architecture can be resource-efficient for small-scale applications that don’t require elaborate infrastructure.
Drawbacks:
- Scalability: Scalability is limited in one-tier architecture due to the tight coupling of all components. Scaling requires replicating the entire application on multiple machines.
- Maintenance Challenges: Modifications to a single component have the potential to impact the entirety of the application. Maintenance becomes complex as the application grows.
- Limited Flexibility: It may not be suitable for applications that need to evolve, incorporate new technologies, or adapt to changing requirements.
- No Centralized Data Management: In larger applications, the lack of centralized data management can lead to data redundancy and inconsistency.
Use Cases:
One-tier architecture is best suited for:
- This architecture is well-suited for compact standalone applications that possess straightforward functionalities.
- Prototyping or proof-of-concept projects.
- This architecture is fitting for applications necessitating deployment on a single machine, devoid of the need for network communication.
Examples:
- Basic calculator applications.
- Simple games.
- Offline utilities.
To sum up, the one-tier architecture serves as a simple approach ideal for small-scale applications, prioritizing simplicity and minimal resource consumption. However, it lacks the scalability and flexibility required for larger, more complex applications that need to accommodate evolving requirements and changing technologies.
2 – Tier Architecture or Client – Server Architecture

Two-tier architecture, also known as the Client-Server architecture, is a software design pattern in which an application is divided into two main components: the client and the server. Each component handles specific functions and responsibilities, resulting in a separation of concerns. Extensively utilized, this architecture serves as the foundation for numerous client-server applications. Now, let’s delve into its characteristics, benefits, and limitations.
Characteristics:
- Client Tier: The client is responsible for presenting the user interface and handling user interactions. It sends requests to the server for data processing or retrieval.
- Server Tier: The server processes client requests, performs business logic, and manages data storage and retrieval. It responds to client requests with the requested data or results.
Advantages:
- Separation of Concerns: Two-tier architecture separates the user interface from the business logic and data management, making the application easier to design and maintain.
- Performance: The division of processing between the client and server can lead to improved performance as tasks are distributed.
- Scalability: The server tier can be scaled independently to handle increased demand without affecting the client.
- Centralized Data Management: The server manages data storage and ensures data consistency and integrity.
Drawbacks:
- Limited Distribution: This architecture assumes that the client and server are on separate machines. Distribution of the client or server components might require significant changes.
- Network Overhead: Communication between the client and server over the network can introduce latency and affect performance.
- Complexity: While simpler than other architectures, two-tier systems can still become complex as the application grows.
Use Cases:
Two-tier architecture is suitable for:
- Client-server applications are particularly beneficial when there’s a requirement to distinctly isolate the user interface from data management and business logic.
- Applications benefiting from centralized data management and ease of maintainability are well-suited for this architecture.
- This architecture is advantageous for scenarios in which the user interface and data processing are separate entities that can function independently.
Examples:
- Web applications with a front-end (browser) and back-end (web server and database).
- Email clients that communicate with email servers.
- Online banking applications where users interact with a client application that communicates with a banking server.
In conclusion, the two-tier architecture stands as a widely adopted pattern for constructing client-server applications. It provides a clear separation between the client and server components, allowing for easier maintenance, scalability, and centralized data management. Nevertheless, it is important to note its constraints in distribution and network communication, which warrant thorough consideration aligned with the application’s needs.
3 – Tier Architecture or Multi – Tier Architecture
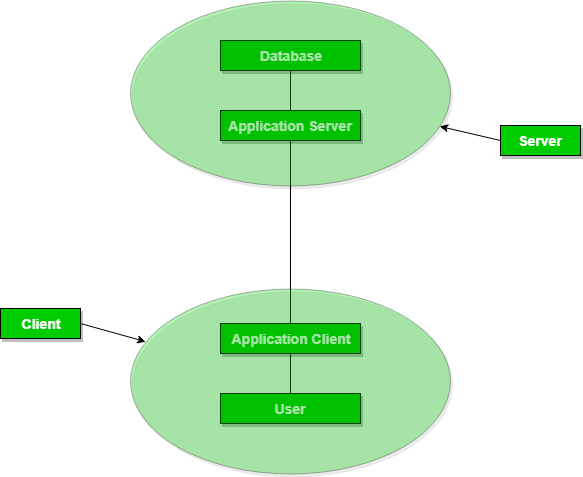
Three-tier architecture, also known as the Multi-Tier architecture, is a software design pattern that divides an application into three main components or tiers: the presentation tier, the application logic tier, and the data storage tier. Each tier has distinct responsibilities and interacts with the others to create a more modular and scalable system. This architecture finds common use in constructing intricate and scalable applications. Let’s explore the characteristics, advantages, and drawbacks of the three-tier architecture.
Characteristics:
- Presentation Tier (Client Tier):
- Responsible for presenting the user interface to the user and handling user interactions.
- Receives user input and sends requests to the application logic tier.
- Typically implemented as a web or desktop interface.
- Application Logic Tier (Middle Tier):
- Contains the business logic and processing logic of the application.
- Receives requests from the presentation tier, processes them, and interacts with the data storage tier.
- Guarantees the independent maintenance of data processing and business rules from the user interface.
- Data Storage Tier (Backend Tier):
- Manages the storage and retrieval of data.
- Stores the application’s data in databases, files, or other storage systems.
- Provides an interface for the application logic tier to access and manipulate data.
Advantages:
- Modularity and Scalability: The clear separation of tiers fosters streamlined maintenance, seamless updates, and enhanced scalability. Each tier has the capability to be developed and scaled autonomously.
- Improved Security: Functioning as a gatekeeper, the application logic tier plays a crucial role in protecting sensitive business logic from being exposed to the presentation tier.
- Flexibility: Changes to one tier do not necessarily impact the others, enabling easier updates and modifications.
- Distributed Development: Different teams can work on each tier simultaneously, facilitating parallel development.
Drawbacks:
- Complexity: The greater number of tiers can potentially introduce intricacies into the design and overall architecture of the system.
- Network Communication Overhead: Inter-tier communication across a network has the potential to introduce latency and impact overall performance.
- Deployment Challenges: Efficient deployment and management of multiple tiers could necessitate increased effort and coordination.
Use Cases:
Three-tier architecture is suitable for:
- This architecture is particularly suitable for accommodating the needs of extensive and intricate applications that prioritize modularity, scalability, and maintainability.
- This architecture is well-suited for applications that demand a distinct segregation between business logic and user interface considerations.
- This architecture is a fitting choice for systems that engage with multiple data sources or services.
Examples:
- E-commerce platforms with separate frontend, backend, and database layers.
- Enterprise resource planning (ERP) systems.
- Online booking systems that involve user interfaces, reservation processing, and data storage.
In summary, three-tier architecture offers a structured approach to building complex applications by dividing them into presentation, application logic, and data storage tiers. This separation allows for modular development, improved scalability, and easier maintenance. However, it also brings about certain complexities and potential network communication overhead that necessitate careful management according to the application’s needs.
Conclusion
In conclusion, the architecture of a Database Management System (DBMS) is a critical foundation that underpins the efficiency, reliability, and functionality of modern data-driven applications. Whether you’re interacting with a website, managing business operations, or conducting analytical research, the DBMS architecture plays a pivotal role in ensuring seamless data management.
Spanning from fundamental components to intricate layer interactions, comprehending DBMS architecture provides valuable insights into these systems’ internal mechanisms.
In conclusion, the architecture of a Database Management System (DBMS) is a critical foundation that underpins the efficiency, reliability, and functionality of modern data-driven applications. Whether you’re interacting with a website, managing business operations, or conducting analytical research, the DBMS architecture plays a pivotal role in ensuring seamless data management.
From fundamental components to intricate layer interactions, comprehending DBMS architecture grants profound insights into the mechanics of these systems.



[…] It allows you to create, retrieve, update, and delete data from databases, as well as define their structure and relationships. SQL is essential for working with data-driven applications and plays a crucial […]